Blog
The 5 Dimensions of AI Quality: A Guide to Scaling AI from Pilot to Production
06 Feb, 2026
- 9 min read
Share On


Last reviewed : 22nd July 2026
Key takeaways
- Since AI operates on probabilities, it does not perform well when assessed with a deterministic perspective. Therefore, the quality of AI should be evaluated using a range of parameters that allow it to operate within guardrails without compromising the quality of its output
- The Five Dimensions – Reproducibility, Factuality, Bias, Drift, and Explainability – establish a reliable environment for an AI model to work effectively
- By defining your AI system, its purpose, and expected outputs, you can tailor the model for corresponding thresholds of the Five Dimensions
- The Five Dimensions work in tandem to ensure the AI model generates relevant outputs and functions within the specified ranges and caveats
AI explainability may seem like a second priority when developing models; however, its impact on final results is far more noticeable than you think. According to McKinsey (2025), data drift and shifting inputs can critically harm even well-calibrated AI systems after deployment.
Talk to our AI Quality experts
Not sure where to begin? Book a 30-Minute AI Quality Engineering Consultation with us and review your AI system architecture and use cases with our AI Quality experts and identify your highest-risk quality gaps
For example: New Scientist (May 2025) reported that OpenAI’s models 01, 03, and 04 sequentially showed increased hallucinations when tasked with summarizing publicly available facts. 01 had a hallucination rate of 16%, 03 a rate of 33%, whereas model 04 had a hallucination rate of a whopping 48%.
This shows how poor explainability, data drift, and incorrect testing practices contribute to problematic results and scaling difficulties.
Consider this scenario:
A Fortune 500 retail bank deployed a GenAI assistant to help relationship managers process loan applications. The system reviewed customer profiles, analyzed supporting documents, flagged risks, and recommended approval decisions with interest rates.
Early results were promising. Application processing time dropped by 40%. The AI sounded fluent, confident, and professional.
Then the quality issues surfaced.
The same applicant, with the same data, received three different outcomes:
- Monday: Loan approved at standard interest rates
- Wednesday: Application flagged as medium risk, additional documentation requested
- Friday: A compliance concern was cited—one that didn’t exist in the source data
Each response looked reasonable in isolation. Collectively, they created operational chaos. Relationship managers lost confidence, approvals slowed due to manual reviews, and audit teams raised concerns about decision defensibility. The system could not move beyond pilot.
Nothing was technically “broken”; this was probabilistic behavior operating without quality guardrails.
This pattern is common. The gap is not model sophistication; it is systematic quality engineering. According to the World Quality Report 2025, 41% organizations report undefined QE organization as a new barrier to scaling AI from pilot to production. The lack of validation strategies for AI is another leading factor affecting 60% of companies adopting this technology.
Why Traditional QA Doesn’t Work for AI
Traditional software testing assumes determinism, whereas AI systems are inherently probabilistic. Traditional QA methods, built for deterministic software, fail when applied to systems that generate variable outputs.
To scale AI safely and confidently, enterprises need a quality framework designed for probabilistic systems – one that makes AI trustworthy, auditable, and deployable.
That framework rests on five dimensions of AI quality.
Traditional software:
Identical inputs → identical outputs
This makes testing straightforward. Validate once, deploy with confidence.
AI systems behave differently:
Identical inputs → variable outputs (within a range)
A generative AI assistant may produce different narratives, recommendations, or risk assessments across runs. This is expected behavior, not a defect.
This behavior changes the key question about quality from “Is this output correct?” to “Can we trust this system to work reliably at scale?”
This shift has real consequences:
- Regulatory exposure: Explainability, fairness, and auditability are legal requirements
- Operational paralysis: Teams cannot automate decisions they can’t defend
- Reputational risk: Fluent but incorrect or biased outputs damage trust
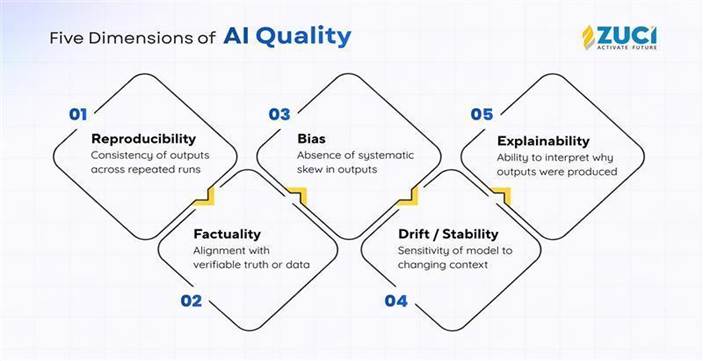
The Five Dimensions of AI Output Quality
The five dimensions of AI quality transform trust from an abstract concern into something observable, testable, and enforceable. Together, they form a connected system of controls that makes probabilistic AI production-ready.
1. Reproducibility: Controlling variance so outputs remain stable and governable
2. Factuality: Ensuring outputs are grounded in verifiable data
3. Bias: Detecting and correcting systematic unfairness across segments
4. Drift: Monitoring quality degradation over time
5. Explainability: Making decisions transparent, auditable, and defensible
Each dimension addresses a distinct failure mode. None of them works in isolation.
Talk to our AI Quality experts
Not sure where to begin? Book a 30-Minute AI Quality Engineering Consultation with us and review your AI system architecture and use cases with our AI Quality experts and identify your highest-risk quality gaps
1. Reproducibility: Establishing a stable baseline
Reproducibility measures whether an AI system produces outputs that remain consistent within defined variance thresholds. It does not eliminate variability; it makes variability measurable and controllable.
Without reproducibility, you cannot reliably assess other quality dimensions.

In one large banking deployment, reproducibility testing revealed 18% variance across identical loan applications—making bias and drift analysis impossible until variance controls were introduced.
How to test for reproducibility?
To test for reproducibility, focus on managing the variance already present in your LLMs. AI systems are probabilistic, which necessitate viewing variance as not something to eliminate, but something to regulate by establishing thresholds and ranges.
Run identical scenarios at scale to establish variance baselines, define thresholds by business criticality, and monitor variance continuously and alert on breaches. Your goal should be to establish guardrails that prevent the output from deviating from the acceptable range.
Webinar: Redefining QE for AI: Testing Probabilistic Systems Deterministically, in Partnership with Everest Group
2. Factuality: Preventing fluent errors
Factuality ensures that every claim an AI makes can be traced back to verified data. Generative systems can produce confident but incorrect statements that pass surface-level review and trigger downstream decisions.

A Lucidworks report (2024) highlights a 5x spike in concerns about AI hallucinations and response accuracy. This emphasizes the dire need for effective factuality scoring of AI models in production.
How to test for factuality?
To test for factuality, it is necessary to test the grounding of the output value. Compare the response with the source data or the information input into the system to gauge whether the AI is straying from the provided context. Use retrieval-augmented generation (RAG) with citation tracking, and apply semantic similarity scoring to validate claims. You can also introduce human review for high-risk decisions.
Download The Determinism Spectrum Framework: Classify your AI system in under 10 minutes and match your testing strategy to your AI system.
3. Bias: Ensuring fair outcomes across all segments
Bias occurs when AI systems perform well in aggregate but systematically disadvantage specific groups. These failures are invisible unless tested deliberately.
Bias is not an ethics problem; it is a technical failure in how patterns are learned and applied.

In one lender’s deployment, approval rates differed by nearly 20 percentage points between salaried and gig workers with identical credit profiles, a gap that went undetected for months.
How to test for bias in AI systems?
Start by disaggregating the AI performance monitoring metrics by segment: behavioral and engineering bias. Run counterfactual tests by changing one attribute at a time to investigate the root cause, such as whether the training data is skewed or if prompts are poorly defined.
Apply fairness metrics (demographic parity, equalized odds) and perform intersectional analysis for compounded bias to determine AI accuracy and biases.
4. Drift: Detecting silent degradation
Drift refers to the gradual decline in AI performance as data, context, or system behavior changes. It rarely triggers alarms and is often discovered only after causing business impact.

Two forms of drift matter:
- Data drift: Input distributions change over time
- Prompt or behavior drift: Outputs shift despite consistent inputs
How to test for drift?
Testing for drift looks similar to regression testing in deterministic systems. Keep retesting your AI system against fixed golden datasets regularly. Monitor statistical indicators like PSI and KL divergence to assess how much the outputs have drifted. Use shadow deployments for updates and initiate automatic rollback when thresholds are breached.
Download The Determinism Spectrum Framework: Classify your AI system in under 10 minutes and match your testing strategy to your AI system.
5. Explainability: Making decisions defensible
Explainability is the ability to articulate why an AI produced a specific outcome. It is mandatory in regulated decision-making.

Explainability turns “the AI said no” into “the AI said no because these factors exceeded policy thresholds.”
How to conduct explainability validation?
Explainability tests focus on reasoning and provenance largely because LLMs are considered “black boxes”. You can start by validating the faithfulness of explanations to model behavior to ensure consistency across similar inputs. Also test explanations for clarity and usability, and maintain audit-ready decision trails. Remember that every output should remain traceable to its specific data source for an AI model to remain “Explainable.”
Why the Five Dimensions Must Work Together
The five dimensions are interdependent. Weakness in one undermines the rest.
- Reproducibility enables bias detection
- Factuality provides ground truth for drift analysis
- Explainability makes bias and drift actionable
Organizations that scale AI treat these dimensions as a connected quality system rather than isolated checks.
Is Your AI Ready for Production?
Get Your Personalized AI Quality Report in Minutes.
Evaluate your system across 5 critical dimensions of AI Quality and uncover the gaps that could affect production performance.
Next steps: Moving From Pilot to Production
You now have the framework. The next question is where your AI system stands, and how to close the gaps. We’ve designed multiple ways to help you do that:
Understand your system’s deterministic nature
Read our blog on our proprietary Determinism Spectrum to learn how to classify the deterministic nature of your AI application and align your testing strategy.
Download The Determinism Spectrum Framework: Classify your AI system in under 10 minutes and match your testing strategy to your AI system.
Learn from the experts
Join Srinivasan Sundharam (Head of GenAI CoE, Zuci Systems), Sujatha Sugumaran (Head of QE Practice, Zuci Systems), and Ankit Nath (Everest Group) as they unpack:
- Why 88% of AI pilots fail to reach production—and what the 12% do differently
- QE maturity stack for AI systems
- Determinism by Design approach to testing AI systems
- Real-world case studies: Banks, healthcare providers, and fintech companies that scaled AI using systematic QE
Webinar: Redefining QE for AI: Testing Probabilistic Systems Deterministically, in Partnership with Everest Group
Need Help Implementing?
At Zuci, we’ve applied the 5 dimensions of AI to help teams move from AI pilots to production with confidence. Our QE for AI services spans:
- AI output quality assurance
- Traditional ML model testing and validation
- AI assurance strategy
- AI business value assurance
Explore our QE for AI services
Talk to our AI Quality experts
Not sure where to begin? Book a 30-Minute AI Quality Engineering Consultation with us and review your AI system architecture and use cases with our AI Quality experts and identify your highest-risk quality gaps
Frequently Asked Questions
Why does drift negatively impact AI model ROI months after launch?
Drift occurs when the world around the AI model changes; in other words, when the AI model does not evolve in response to changing needs. AI pilots do prove a concept, but it is only through continuous evaluation loops that you can monitor the concept drifts, without which your AI output quality is bound to decay over time.
This leads to a loss of user trust, which is harder to rebuild than establish.
Can AI be scaled to production without a human-in-the-loop strategy?
What is a “Silent failure” and how can I prevent it?
Can I remove bias by simply eliminating sensitive attributes from training data?
Is it possible to provide explainability without overwhelming the end user?
Talk to our AI Quality experts
Not sure where to begin? Book a 30-Minute AI Quality Engineering Consultation with us and review your AI system architecture and use cases with our AI Quality experts and identify your highest-risk quality gaps
About Zuci Systems
Zuci Systems is an AI-first digital transformation partner specializing in quality engineering for AI systems. Named a Major Contender by Everest Group in the PEAK Matrix Assessment for Enterprise QE Services 2025 and Specialist QE Services, we’ve validated AI implementations for Fortune 500 financial institutions and healthcare providers.
Our QE practice establishes reproducibility, factuality, and bias detection frameworks that enable enterprise-scale AI deployment in regulated industries.
Author's Profile

Head, Gen Al Center of Excellence, Zuci Systems
![]()
Srinivasan heads Zuci’s Generative AI Center of Excellence, leading initiatives that unite AI, engineering, and enterprise transformation.
With over 20 years of experience in technology strategy and digital platforms, he helps organizations design scalable AI systems that balance creativity and control.
Share On
Is Your Bank Ready for MLOps? Here’s How to Find Out
The Determinism Spectrum: Why AI Can’t Be Tested Like Just Another Software
Author’s Profile

Head, Gen Al Center of Excellence, Zuci Systems|![]()


