Temps de lecture : 1 Minutes
OCR – Reconnaissance Optique de Caractères

I write about fintech, data, and everything around it
Un problème majeur auquel de nombreuses entreprises sont confrontées aujourd’hui est l’incapacité de récupérer des données qui sont piégées dans des documents et des images numérisés. Il existe deux manières d’extraire les données :
- Extraction manuelle des données
- Extraction de données automatisée
Étant donné que le processus manuel présente de nombreux inconvénients, nous avons besoin d’un logiciel d’automatisation de la saisie de données qui aide à extraire les données des documents numérisés et à les automatiser en fonction des processus métier.
Le défi n’est pas seulement d’extraire les données des documents numérisés, mais aussi de les extraire avec précision. Les systèmes automatisés de saisie de données sont capables de lire des informations provenant de différentes sources de données (fichiers PDF, documents imprimés, e-mails, sites Web, …) et d’ingérer les données dans un stockage de données plus adapté (bases de données, fichiers tableur, …).
L’ OCR est l’un de ces logiciels/technologies. La reconnaissance optique de caractères, ou OCR, est une technologie qui vous permet de convertir différents types de documents, tels que des documents papier numérisés, des fichiers PDF ou des images capturées par un appareil photo numérique, en données modifiables et interrogeables. Pour ceux qui ont commencé à explorer les applications Android OCR, cet article vous aidera à explorer la recherche d’OCR en tant qu’application Android permettant de convertir des données manuscrites et imprimées dans des images en texte .
Qu’est-ce que l’OCR et comment ça marche ?
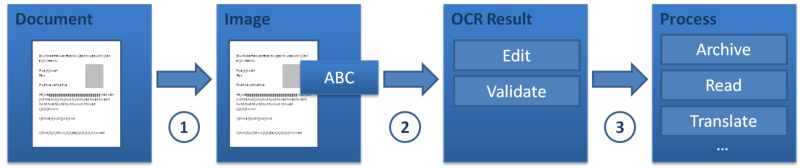
OCR-lecteur de caractères optique/reconnaissance
Optical Character Reader (OCR) est un logiciel qui utilise la reconnaissance optique de caractères pour lire des caractères spécifiques sur des feuilles et les convertir en caractères numériques. Le logiciel OCR peut être utilisé pour convertir des données imprimées en données numériques sans saisie, par exemple à partir d’un document numérisé. Il est très utile lorsqu’il est nécessaire de numériser du texte à partir de livres, de documents numérisés, etc. Une fois que l’OCR a extrait le texte, il peut être copié ou enregistré dans différents formats.
Flux de travail :
Capturer l’image, détecter les bords, récupérer le texte d’une image, traduire à l’aide de l’API Google et lancer le résultat.
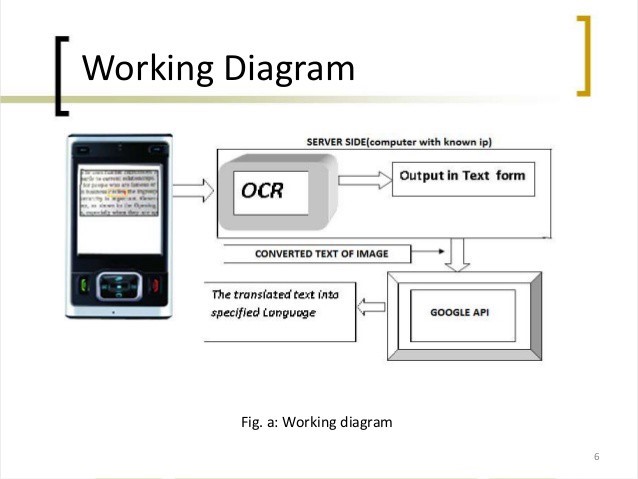
Nous avons besoin d’une application Android, qui doit supporter les contraintes suivantes :
- Numériser le texte du contenu manuscrit
- Avoir un support API
- Bénéficiez de l’assistance de la trousse d’outils
- Bénéficiez d’un support pour l’apprentissage automatique ou l’apprentissage profond
Moi-même, avec mon équipe, avons pris quelques exemples d’images de google pour vérification. Avec ces exemples d’images, nous avons effectué des expériences avec diverses applications Android, telles que
- CamScanner
- TexteFée
- Google Keep
- Scanner de texte OCR
- Analyseur de texte
- Lentille de bureau
- ROC en ligne
- Numériseur Adobe
- Numérisation Evernote
- Espace ROC
- API Google

Fig.b.capture d’une image de texte pour la conversion
En plus de l’exemple d’image, nous avons besoin d’un code de détection de texte pour tester le processus. La détection de texte effectue la reconnaissance optique des caractères. Il détecte et extrait le texte d’une image avec la prise en charge d’un large éventail de langues. Il dispose également d’une identification automatique de la langue. Le code de détection de texte (JAVA) que nous avons utilisé pour notre projet est partagé ci-dessous :
public static void detectText(String filePath, PrintStream out) lance une exception, IOException {
Demandes de liste = nouvelle ArrayList<>();ByteString imgBytes = ByteString.readFrom(nouveau FileInputStream(filePath));
Image img = Image.newBuilder().setContent(imgBytes).build();
Feature feat = Feature.newBuilder().setType(Type.TEXT_DETECTION).build();
Requête AnnotateImageRequest =
AnnotateImageRequest.newBuilder().addFeatures(feat).setImage(img).build();
demandes.add(demande);essayez (client ImageAnnotatorClient = ImageAnnotatorClient.create()) {
BatchAnnotateImagesResponse réponse = client.batchAnnotateImages(demandes);
Liste des réponses = response.getResponsesList();for (AnnotateImageResponse res : réponses) {
si (res.hasError()) {
out.printf(“Erreur : %sn”, res.getError().getMessage());
revenir;
}// Pour obtenir la liste complète des annotations disponibles, consultez https://g.co/cloud/vision/docs
pour (annotation EntityAnnotation : res.getTextAnnotationList()) {
out.printf(“Texte : %sn”, annotation.getDescription());
out.printf(“Position : %sn”, annotation.getBoundingPoly());
}
}
}
}
Selon notre exploration, toutes les applications décrites ci-dessus ont la capacité de numériser la prescription imprimée en PDF, mais elles n’ont pas réussi à numériser l’écriture manuscrite. Pour surmonter ce problème, nous avons fait des recherches et trouvé que l’ICR et l’IWR aident à résoudre ce problème.
Que sont l’ICR et l’IWR ?

RIC
La reconnaissance intelligente de caractères ( ICR ) est une reconnaissance optique de caractères avancée ou plutôt un système de reconnaissance d’écriture manuscrite plus spécifique qui permet à un ordinateur d’apprendre des polices et différents styles d’écriture manuscrite pendant le traitement afin d’améliorer la précision et les niveaux de reconnaissance (apprentissage automatique / approfondi).

IWR
La reconnaissance intelligente des mots (IWR) peut reconnaître et extraire non seulement les informations manuscrites imprimées, mais également l’écriture manuscrite cursive. L’ICR reconnaît le niveau des caractères, tandis que l’IWR fonctionne avec des mots ou des phrases complets. Capable de capturer des informations non structurées à partir de pages de tous les jours, l’IWR serait plus évolué que l’ICR d’empreintes digitales.
Sommaire :
Cet article a couvert de nombreux avantages et inconvénients de diverses applications Android OCR pour convertir une image en texte, ainsi que sur ICR, IWR. Je partagerai les résultats expérimentés des applications respectives dans mon prochain blog.
Merci d’avoir lu et restez à l’écoute pour en savoir plus. :)
Articles connexes



















")