Blog
The Three Most Common AI Testing Mistakes (And How to Fix Them Before Production)
10 Feb, 2026
- 11 min read
Share On


Last reviewed : 22nd July 2026
Key takeaways
- Most AI testing environments still rely on traditional testing principles, which are rigid at best. This static testing methodology creates a logic gap between probabilistic AI systems and accurate evaluation
- When scaling AI, three fatal testing mistakes lead to the derailment of production:
- Demanding creative systems to be precise
- Allowing deviations in systems expected to be mathematically perfect
- Thinking that AI testing is a one-time thing
- AI systems are probabilistic by nature and require testing methodologies that achieve predictability through design and validation.
- QE must evolve beyond assurance of code to assurance of intelligence – the foundation for measurable trust.”
- Avoid the three common AI testing pitfalls with a two-step approach:
- Classify your AI system – Determine which of the four zones (deterministic to creative) your system belongs to based on its designed predictability
- Test the right dimensions – Focus on the quality dimensions (Reproducibility, Factuality, Bias, Drift, Explainability) that matter for your zone
Download The Determinism Spectrum Framework: Classify your AI system in under 10 minutes and match your testing strategy to your AI system.
While AI innovations and development are advancing at full speed, it seems testing approaches for these systems remain largely traditional.
In deterministic systems, testing yields black-and-white results. However, AI systems are more probabilistic; traditional testing methods are not the most suitable vantage point for gaining a full perspective on AI system outcomes.
AI testing mistakes are more commonplace than you realize. Here’s a scenario playing out in enterprises right now:
A marketing team deploys generative AI to create email campaigns. The system works beautifully: creative, on-brand, engaging. Then QE runs their standard tests to find 100 identical prompts. The outputs vary. QE flags “inconsistency” as a critical defect.
The AI project stalls.
The QE team wasn’t wrong to test for consistency. They were testing the wrong kind of AI system.
According to recent NTT Data research (2025), 75%-80% of AI deployments fail to reach their expected outcomes. Teams either over-test creative systems (flagging natural variance as defects) or under-test deterministic systems (accepting unacceptable variance as “just how AI works”).
The core issue is that not all AI systems should behave the same way, and they can’t be tested the same way either.
Talk to our AI Quality experts
Not sure where to begin? Book a 30-Minute AI Quality Engineering Consultation with us and review your AI system architecture and use cases with our AI Quality experts and identify your highest-risk quality gaps
Let’s break down the three most common mistakes.
Mistake #1: Testing creative AI like it’s a calculator

The Scenario
Your marketing team deploys AI to generate variations for email campaigns. The goal: create 100 different emails that are all on-brand but varied enough to test which messaging resonates.
Your QE team runs 100 identical prompts. They get 100 different outputs. They flag “inconsistency” as a critical defect and block the release.
Why It’s Wrong
The system was designed to be creative. Variation was the goal, not a bug.
This is like testing a human copywriter by asking them to write the same email 100 times and calling it a failure when each version is different. The “defect” QE flagged is actually the feature the marketing team needs.
The result? Projects stall while teams debate whether variance is acceptable, wasting weeks arguing over a testing mismatch.
The Real Issue
You’re applying deterministic testing (expecting identical outputs) to a creative system (designed for varied outputs).
Download The Determinism Spectrum Framework: Classify your AI system in under 10 minutes and match your testing strategy to your AI system.
Talk to our AI Quality experts
Not sure where to begin? Book a 30-Minute AI Quality Engineering Consultation with us and review your AI system architecture and use cases with our AI Quality experts and identify your highest-risk quality gaps
Mistake #2: Accepting variance in systems that should be exact
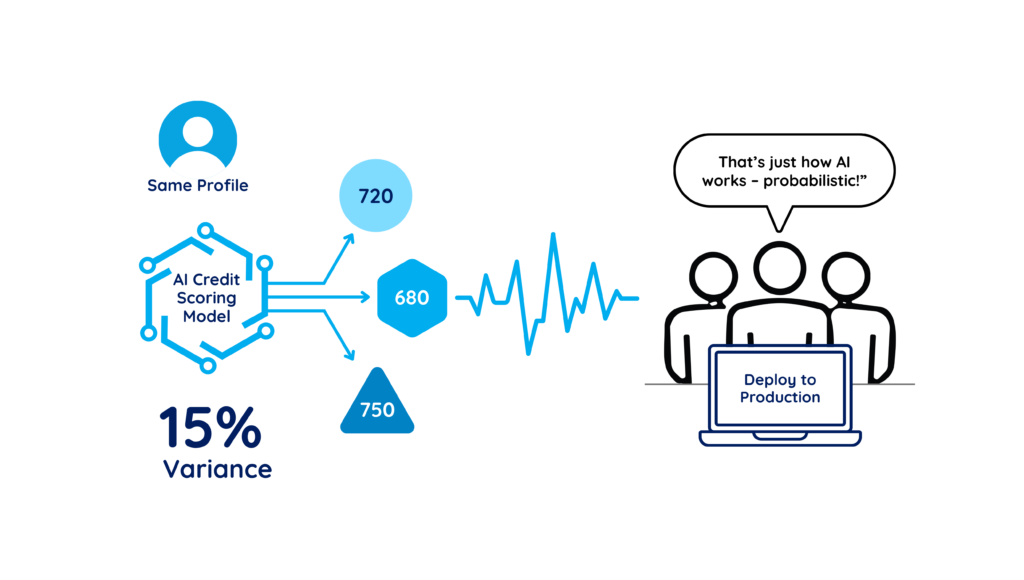
The Scenario
Your credit-scoring AI shows a 15% variance when testing the same customer profile multiple times. Some runs return 720, others 680, others 750.
When flagged, someone says: “That’s just how AI works; it’s probabilistic.” The team accepts the variance and moves to production.
Why It’s Wrong
Credit scoring must be exact. The same customer profile should always produce the same score. If it doesn’t:
- Regulatory risk: Regulators reject systems that can’t explain why identical customers get different scores
- Legal exposure: Customers can challenge inconsistent decisions
- Trust erosion: Business stakeholders lose confidence in AI
This isn’t “AI being probabilistic.” This is a configuration error, model drift, or architectural flaw.
The Real Issue
You’re treating a deterministic system (must be 100% reproducible) like it’s a probabilistic system (some variance is acceptable).
Also Read: The 5 Dimensions of AI Quality: A Guide to Scaling AI from Pilot to Production
Mistake #3: Testing once and assuming it stays fixed

The Scenario
Your AI chatbot works beautifully at launch. QE thoroughly validates it: 95% accuracy, excellent quality, and high customer satisfaction.
You deploy. You move on to the next project.
Six months later, customer complaints spike. The chatbot has become verbose, sometimes gives outdated information, and occasionally misunderstands simple questions. No one was monitoring it.
Why It’s Wrong
AI systems drift over time; it changes even when you don’t touch it.
- User behavior evolves
- Input patterns shift
- External context changes
- Model performance degrades subtly
One-time validation catches launch issues. It won’t catch drift six months later.
The Real Issue
You’re applying a one-time validation (a traditional software approach) to systems that require continuous monitoring (AI systems that drift).
The root cause: one testing approach for all AI
These three mistakes share a common problem: teams apply traditional software testing principles to all AI systems without adapting for how AI actually behaves.
Traditional software testing assumes:
- Fixed logic that doesn’t change
- 100% reproducibility as the standard
- One-time validation is sufficient
- Pass/fail binary outcomes
But AI systems don’t all work this way. Some AI must be deterministic (e.g., credit scoring), while others are designed to vary (e.g., creative content). All of them drift over time.
The solution isn’t more rigorous testing. It’s more precise testing based on what your AI system is designed to do.
Talk to our AI Quality experts
Not sure where to begin? Book a 30-Minute AI Quality Engineering Consultation with us and review your AI system architecture and use cases with our AI Quality experts and identify your highest-risk quality gaps
The fix: Zuci’s proprietary AI testing frameworks
At Zuci, we’ve developed two frameworks that solve these testing mismatches:
- The Determinism Spectrum – Classifies AI systems by how predictable they should be
- The Five Dimensions of AI Quality – Defines what to test based on system type
Together, these frameworks give you a clear, defensible testing strategy that satisfies QE teams, regulators, and business stakeholders.
Framework #1: The Determinism Spectrum
The Determinism Spectrum classifies AI systems into four zones based on how predictable their outputs should be:
Zone 1 → Fully deterministic
AI systems in this zone must produce identical outputs for identical inputs. For example, credit scoring, tax calculation, and rule-based fraud detection systems.
Zone 2 → Mostly predictable
These systems reason based on context. For example, ML-based fraud-detection and risk-assessment systems.
Zone 3 → Contextually creative
These systems generate recommendations that humans act on. For example, content generation, chatbots, and AI summarization systems.
Zone 4 → Highly creative
These systems generate creative, open-ended outputs. For example, marketing ideation, design generation, and brainstorming tools.
Download The Determinism Spectrum Framework: Classify your AI system in under 10 minutes and match your testing strategy to your AI system.
How this fixes the three QA automation mistakes
This framework evaluates your AI systems for what they are designed to do.
Mistake #1 (Testing creative AI like a calculator)
Your marketing email system is Zone 3 or 4. Stop testing for reproducibility. Instead, test for brand alignment, bias, and consistency in quality.
Mistake #2 (Accepting variance in deterministic systems)
Your credit scoring system is Zone 1. Demand 100% reproducibility. Any variance is a defect that must be investigated immediately.
Mistake #3 (One-time testing)
Your chatbot is in Zone 3. It will drift. Set up monthly monitoring with human evaluation sampling to catch degradation before users do.
19 questions. 10 minutes. One personalized report.
Benchmark your AI across 7 quality dimensions and discover what’s blocking production confidence.
📖 Read the complete framework: The Determinism Spectrum: A Framework for Classifying AI Systems
Framework #2: The Five Dimensions of AI Quality
Once you know your system’s zone, you need to know WHAT to test. The Five Dimensions framework defines quality across:
- Reproducibility: Output consistency (critical for Zones 1-2)
- Factuality: Preventing hallucinations (critical for Zones 1-3)
- Bias: Fairness across segments (critical for all zones)
- Drift: Performance over time (critical for all zones)
- Explainability: Auditable decisions (critical for regulated industries)
How this fixes the three mistakes
This framework helps you understand which parameters to test in your AI system.
Mistake #1 (Testing creative AI like a calculator)
Stop testing Zone 3/4 systems for Reproducibility. Focus on Bias and Explainability instead.
Mistake #2 (Accepting variance in deterministic systems)
Zone 1 systems must score perfectly on Reproducibility and Factuality. No exceptions.
Mistake #3 (One-time testing)
All zones need continuous Drift monitoring. Your monitoring frequency depends on your zone (weekly for Zone 4, monthly for Zone 3, quarterly for Zone 1-2).
📖 Read the complete framework: The Five Dimensions of AI Quality: A Practical Guide
How to use these frameworks to fix your testing strategy
By utilizing Zuci’s AI classification framework and Five Dimensional testing methodologies, it is possible systematically remove testing mismatches and errors. This integrated approach helps you evaluate your AI using the precise metrics and parameters aligned with its specific function.
Step 1: Identify Your Problem
Which of these sounds familiar?
- “Our QE and product teams keep debating whether variance is a defect”: You’re making Mistake #1 or #2
- “Our AI worked great at launch, but quality has degraded”: You’re making Mistake #3
- “Regulators are asking why we can’t reproduce our AI’s decisions”: You’re making Mistake #2
- “We’re blocking deployment because outputs aren’t identical”: You’re making Mistake #1
Talk to our AI Quality experts
Not sure where to begin? Book a 30-Minute AI Quality Engineering Consultation with us and review your AI system architecture and use cases with our AI Quality experts and identify your highest-risk quality gaps
Step 2: Classify Your System
Does your system give different answers to the same question?
- If this behavior is unacceptable, your system is Zone 1 (fully deterministic)
- If some variance is acceptable, your system is Zone 2 (mostly predictable)
- If you’re okay with variance within a range, your system is Zone 3 (contextually creative)
- If your goal is maximum creativity, your system is Zone 4 (highly creative)
Step 3: Apply the Right Testing Approach
Once you know your zone, you know what to test:
| Your Zone | Test For | Don’t Test For |
| Zone 1 | Reproducibility + Factuality | Creative variance |
| Zone 2 | Factuality + Drift | Minor score variations |
| Zone 3 | Bias + Explainability + Drift | Output reproducibility |
| Zone 4 | Bias + Explainability | Creative diversity |
Get the complete frameworks
- The Determinism Spectrum: How to Classify Any AI System
- The Five Dimensions of AI Quality: What to Test for Each Zone
- AI Output Quality Assessment: Evaluate Your System Across Five Critical AI Quality Dimensions
Need expert help?
Book a 30-minute strategy session with our AI quality engineering team to:
- Classify your AI systems accurately
- Identify testing gaps and mismatches
- Build a zone-specific testing roadmap
Frequently asked questions about AI testing mistakes
How do I measure correctness if there isn’t one “right answer”?
Can guardrails solve the precision problem without hindering creativity?
What is the reason for the deviation in the exact systems in production?
Does variance impact regulatory compliance?
How often should I test my AI systems?
About Zuci Systems
Zuci Systems is an AI-first digital transformation partner specializing in quality engineering for AI systems.
Named a Major Contender by Everest Group in the PEAK Matrix Assessment for Enterprise QE Services 2025 and Specialist QE Services, we’ve validated AI implementations for Fortune 500 financial institutions and healthcare providers.
Our QE practice establishes reproducibility, factuality, and bias detection frameworks that enable enterprise-scale AI deployment in regulated industries.
Need Help Implementing?
At Zuci, we’ve applied the 5 dimensions of AI to help teams move from AI pilots to production with confidence.
Our QE for AI services spans:
- AI output quality assurance
- Traditional ML model testing and validation
- AI assurance strategy
- AI business value assurance
Explore our QE for AI services.
Share On
The Determinism Spectrum: Why AI Can’t Be Tested Like Just Another Software
What Is a Multi-agentic System? A Clear Breakdown Of The 6 Core Building Blocks
Author’s Profile

Head, Quality Engineering, Zuci Systems|![]()



