Blog
From Pilot to Enterprise Scale: Making AI Systems Production-Ready - Blog 5 of 5
22 May, 2026
- 9 min Read
Share On


Key Takeaways
- Governance and observability deferred during the pilot will require re-architecture at scale.
- At enterprise scale, quality assurance becomes a continuous production discipline. Reproducibility, factuality, and drift have to be measured in live operation
- AI systems improve from production interactions. Without governed boundaries on that learning, the same mechanism that improves the system drifts it away from the behavior it was validated for.
- AI cost at scale is driven by model selection and interaction patterns. Organizations that manage it at the interaction level make optimization decisions that system-level budget tracking cannot surface.
What makes a pilot stable is also what limits what it can tell you. The user base is controlled, inputs are curated, and someone is actively managing edge cases. At enterprise scale those conditions are gone, and the system encounters variability, failure modes, and usage patterns it was never designed for.
The governance, observability, and quality assurance mechanisms that determine whether the system holds up under those conditions have to be architectural decisions. Organizations that defer them find out what they cost at the moment the system is already operating across the business at scale.
This is the fifth and final article in a five-part series on the enterprise AI journey. The series opens with why AI programs stall before they pick the right problem, then covers the filter that separates viable candidates from ideas that cannot survive a POC, followed by how to sequence a filtered shortlist into a funded roadmap, and then the execution model for moving a prioritized use case to a working MVP in 9 to 12 weeks. This article covers the control layer that determines whether a validated system remains trustworthy as scale increases.
Why Pilots Do Not Scale Easily
Pilot implementations demonstrate the potential of AI, but they operate within a controlled and constrained environment. Scope is limited, user interactions are predictable, and edge cases are either minimal or actively managed. As a result, the system appears stable, reliable, and effective.
This stability often does not hold when the solution is scaled.
As your user base grows and the system is exposed to a wider range of inputs and scenarios, several challenges begin to emerge. Variability in data quality and structure increases, leading to inconsistent outputs. User behavior becomes less predictable, introducing edge cases that were not encountered during the pilot. A system that was once well-understood begins to behave in ways that are harder to anticipate and control.
At the same time, the impact of failure increases significantly. In a pilot, incorrect outputs can be reviewed, corrected, or contained. At enterprise scale, those outputs can directly influence decisions, customer interactions, and operational processes, making reliability and consistency critical.
Another key challenge is the lack of visibility. Many pilot implementations do not include comprehensive monitoring or observability mechanisms. As a result, when the system scales, your organization struggles to answer fundamental questions: How is the system performing? Where are failures occurring? What is the cost of each interaction? Without this visibility, managing and improving the system becomes difficult.
Governance and control mechanisms that are often deferred during the pilot stage also become essential at scale. Questions around data access, compliance, auditability, and decision traceability need to be addressed to ensure the system can operate within enterprise and regulatory expectations.
Finally, scaling introduces the need for continuous evolution. Unlike traditional systems, AI-driven solutions are not static. They require ongoing refinement of prompts, thresholds, guardrails, and models to maintain performance as conditions change. Without structured mechanisms for learning and improvement, system quality can degrade over time.
A successful pilot validates the idea. Scaling requires a system of control.
5 Principles for Enterprise Scaling
Scaling AI systems from pilot to enterprise requires a shift from experimentation to controlled, reliable operation. Our approach is guided by five principles that ensure systems remain effective as they grow in scope and impact.
- Controlled Autonomy
AI systems should not operate with unchecked autonomy. Clear boundaries must be defined for where AI can act independently and where human oversight or deterministic control is required. - Determinism Where It Matters
Critical workflows, validations, and decision enforcement should remain deterministic, ensuring consistency, predictability, and auditability at scale. - Continuous Validation, Not One-Time Testing
System quality must be continuously monitored and validated. What works during a pilot may degrade over time without ongoing checks for reliability, consistency, and drift. - Observability by Design
Visibility into system behavior, performance, and cost should be built in from the start, enabling proactive monitoring and faster issue resolution. - Learning with Guardrails
AI systems should continuously improve based on real-world interactions, but within controlled boundaries to prevent unintended behavior or drift.
Together, these principles ensure that scaling is not just about expanding usage, but about building systems that remain trustworthy, measurable, and under control at enterprise scale.
The Enterprise AI Control Layer
Scaling an AI system from pilot to enterprise requires more than expanding its reach. It requires the introduction of a comprehensive control layer that ensures the system remains reliable, secure, and aligned with business expectations as complexity increases.
This control layer operates across multiple dimensions, working together to provide stability, visibility, and continuous improvement at scale.
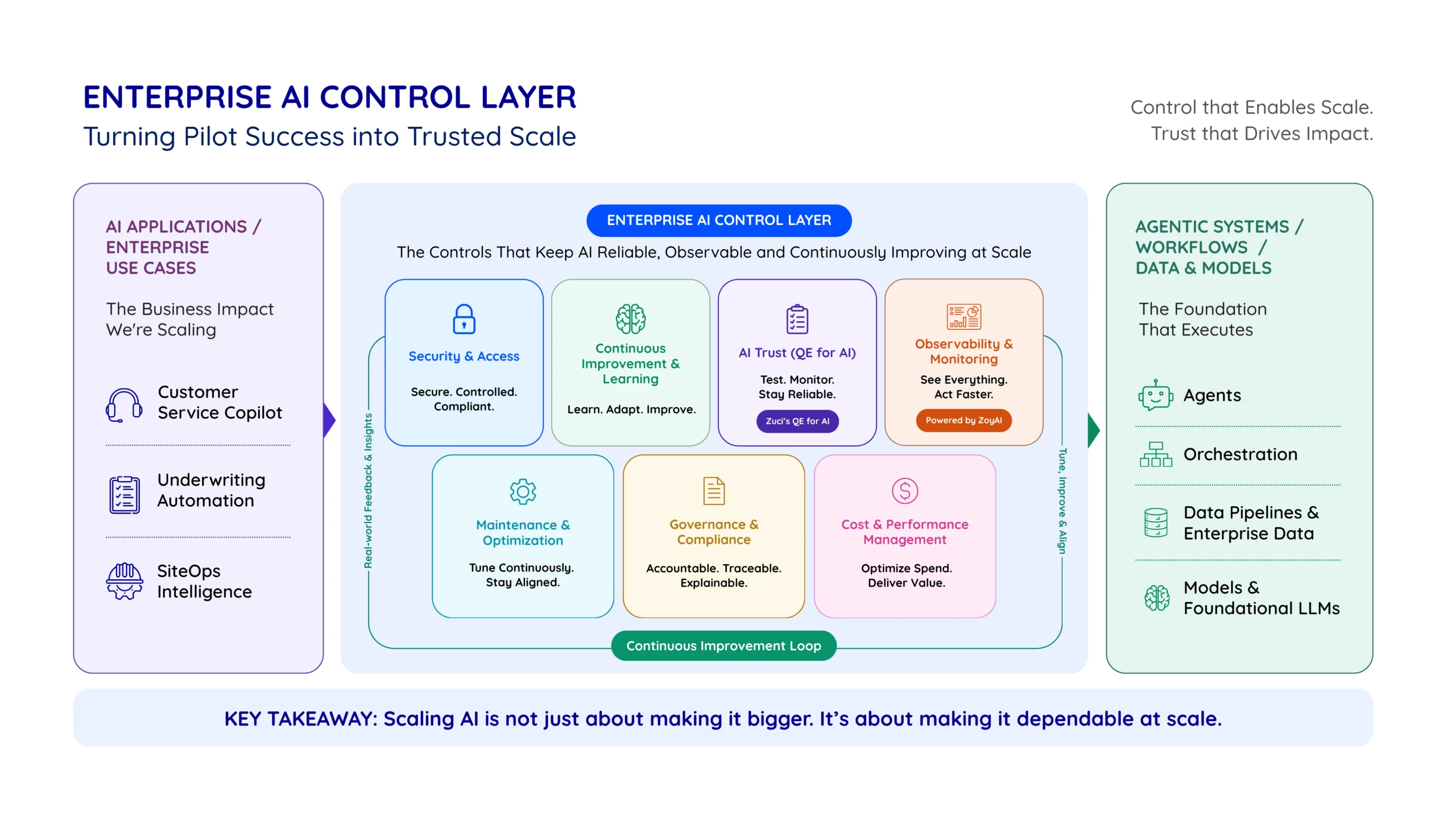
1. Security and Access Control
As AI systems scale across larger user bases, including internal users and external customers, ensuring secure and controlled access becomes critical.
This includes enforcing role-based access controls, managing authentication and authorization, and ensuring that sensitive data is handled appropriately across interactions. As the system integrates with enterprise data sources and workflows, it must also align with existing security frameworks and policies.
In practice, this requires embedding security considerations directly into the architecture, rather than treating them as an external layer.
2. Continuous Improvement and Learning
At enterprise scale, AI systems must continuously evolve based on real-world usage. This requires a structured learning approach that goes beyond ad-hoc updates.
Our approach is anchored in a multi-layered learning framework:
- Autonomous learning through real-world interactions and usage patterns
- Human-assisted learning through human-in-the-loop (HITL) interventions and user feedback
- System-level improvements driven by continuous monitoring of performance and behavior
These feedback loops collectively enable the system to refine how it interprets context, makes decisions, and generates outputs.
Importantly, this learning is controlled and governed, ensuring that improvements are introduced deliberately without causing unintended drift or variability.
3. AI Trust and Quality Assurance
Ensuring consistent and reliable output is one of the most critical requirements at scale. AI systems must be continuously evaluated to maintain trust in their outputs.
We apply a structured approach through Zuci’s QE for AI framework, which measures system output quality across key dimensions:
- Reproducibility: consistency of outputs across similar inputs
- Factuality: correctness and grounding of responses
- Drift: stability of performance over time in production
This moves quality assurance from a one-time validation activity to continuous testing and monitoring, ensuring that system outputs remain consistent, reliable, and aligned with expectations even as usage evolves.
4. Observability and Monitoring
As systems scale, visibility into their behavior becomes essential. Observability provides insights across multiple layers, including workflows, agent interactions, outputs, cost, and performance.
This is enabled through ZoyAI, Zuci’s observability solution, which monitors AI applications across critical dimensions:
- Workflow and agentic performance
- Output quality
- System performance and latency
- Cost and resource utilization
Real-time dashboards and alerts enable your teams to proactively identify anomalies, understand system behavior, and make informed decisions on optimization and scaling.
5. Maintenance and Optimization
AI systems require continuous tuning to remain aligned with business goals as they scale.
This involves refining prompts, thresholds, and guardrails, as well as adjusting system behavior based on evolving requirements. Importantly, this is not done in isolation. It is driven by continuous insights from observability.
Through solutions like ZoyAI, your teams are able to continuously monitor business KPIs alongside system-level metrics such as guardrail adherence and threshold performance. These insights enable ongoing fine-tuning to ensure the system remains aligned with desired business outcomes.
6. Governance and Compliance
As AI systems become embedded in business processes, governance becomes a critical requirement.
This includes maintaining audit trails, ensuring decision traceability, and enabling explainability for system outputs. The ability to demonstrate how decisions are made is essential for meeting enterprise and regulatory expectations.
Embedding governance into the system design ensures that compliance is not an afterthought, but an integral part of how the system operates.
7. Cost and Performance Management
At enterprise scale, cost and performance become key operational considerations.
AI systems, particularly those leveraging large models, can incur significant costs if not actively managed. Monitoring usage patterns, optimizing model selection, and balancing performance with cost efficiency are essential to ensure sustainable operation.
A structured approach to cost and performance management ensures that scaling does not come at the expense of efficiency.
Together, these control layers transform an AI solution from a working pilot into a production-ready enterprise system. They ensure that as the system scales, it remains secure, observable, continuously improving, and aligned with business and regulatory expectations.
Scaling AI successfully requires as much focus on control and trust as it does on capability.
Ready to move a prioritized use case into execution?
See how Zuci’s Idea to MVP delivery model takes enterprise teams from validated use case to working MVP in 9-12 weeks, with enterprise readiness built in from the start.
What Changes from MVP to Enterprise Scale
The transition from MVP to enterprise scale is not just a matter of expanding usage. It represents a shift in how the system is expected to operate.
During the MVP stage, the focus is on validating value within a controlled environment. Scope is limited, user interactions are predictable, and the system is closely monitored. At enterprise scale, these constraints no longer hold. The system must handle a significantly larger and more diverse set of users, operate across a wider range of scenarios, and deliver consistent performance under varying conditions.
This shift introduces new expectations across multiple dimensions.
| MVP | Enterprise Scale |
|---|---|
| Limited users and controlled inputs | Large, diverse user base with variable inputs |
| Defined scenarios and use cases | Wide range of edge cases and evolving scenarios |
| Basic monitoring and validation | Continuous observability and real-time monitoring |
| Static configurations | Continuous learning and optimization |
| Contained impact of errors | High impact on business operations and customer experience |
At its core, this transition is about moving from a validated capability to a trusted, operational system.
By introducing the right control layers spanning security, governance, observability, quality assurance, and continuous improvement, you can ensure that your AI systems not only scale, but do so in a way that is reliable, efficient, and aligned with enterprise expectations.
Scaling AI is not about making it bigger. It is about making it dependable at scale.
Where to Go From Here
This is the final blog in this series on the enterprise AI journey. The series covers the full journey from AI strategy and use case identification through to MVP delivery and enterprise scale.
- Blog 1 – Building the decision-making infrastructure before you pick a use case
- Blog 2 – The 6-filter framework for separating viable candidates from expensive distractions
- Blog 3 – The 2×2 matrix for sequencing your first investments
- Blog 4 – Zuci’s 3-stage execution model for delivering a production-ready MVP in 9-12 weeks
If you are ready to move from pilot to enterprise scale, or are designing a new AI system and want to build the control layer in from the start, talk to the Zuci team.
About Zuci Systems
Zuci Systems is an AI-first digital transformation partner specializing in quality engineering for AI systems. Named a Major Contender by Everest Group in the PEAK Matrix Assessment for Enterprise QE Services 2025 and Specialist QE Services, we’ve validated AI implementations for Fortune 500 financial institutions and healthcare providers.
Our QE practice establishes reproducibility, factuality, and bias detection frameworks that enable enterprise-scale AI deployment in regulated industries.
Explore more at Zuci Systems
Frequently Asked Questions
1. How do you scale an AI system from pilot to production without rebuilding it?
Systems that scale without a rebuild are designed with production constraints in mind from the MVP stage. Governance, observability, and human-in-the-loop controls built into the architecture carry forward. Systems that require a rebuild are the ones validated for a controlled environment and never hardened for what production actually introduces.
2. Why do AI systems that worked in a pilot fail in production?
3. How do you maintain AI quality in production over time?
4. What does AI governance look like at enterprise scale?
5. How should enterprises manage AI costs at scale?
Share On
Enterprise AI Development: A Structured Path from Idea to MVP - Blog 4 of 5
Why Enterprise AI Needs a Context Graph: The Missing Knowledge Substrate
Author’s Profile

Head, Gen Al Center of Excellence, Zuci Systems|![]()
Author's Profile

Head, Gen Al Center of Excellence, Zuci Systems
![]()
Srinivasan heads Zuci’s Generative AI Center of Excellence, leading initiatives that unite AI, engineering, and enterprise transformation.
With over 20 years of experience in technology strategy and digital platforms, he helps organizations design scalable AI systems that balance creativity and control.


