Leestijd : 0 minuten
Kunstmatige intelligentie en gegevenskwaliteit: de vraag van een miljoen dollar

Bibliophile, Movie buff & a Passionate Storyteller.
Een vraag die vaak naar voren komt in de context van het bouwen van kunstmatige-intelligentiesystemen zoals machine learning is : “Hoe krijg je goede data om de algoritmen te trainen? Datakwaliteit is een uitdaging. Hoe overwinnen we het?”
Zowel gegevenshoeveelheid als gegevenskwaliteit zijn even belangrijk voor kunstmatige-intelligentiesystemen . Hoewel opties zoals voorverpakte gegevens, openbare crowdsourcing en privé-crowds worden overwogen om het probleem van de gegevenskwantiteit aan te pakken, blijft gegevenskwaliteit een uitdaging en zal deze waarschijnlijk steeds belangrijker worden.
Waarom gegevenskwaliteit belangrijk is
Systemen zoals Machine Learning en Deep Learning gebruiken zeer grote datasets voor zowel trainings- als testdoeleinden. Het gebruik van gegevens van slechte kwaliteit of irrelevante gegevens om uw machine learning-systeem te trainen, zou een aanzienlijke impact hebben op het gedrag van het systeem. Als uw trainingsgegevens “vuilnis” zijn, zullen de modelresultaten niet anders zijn.
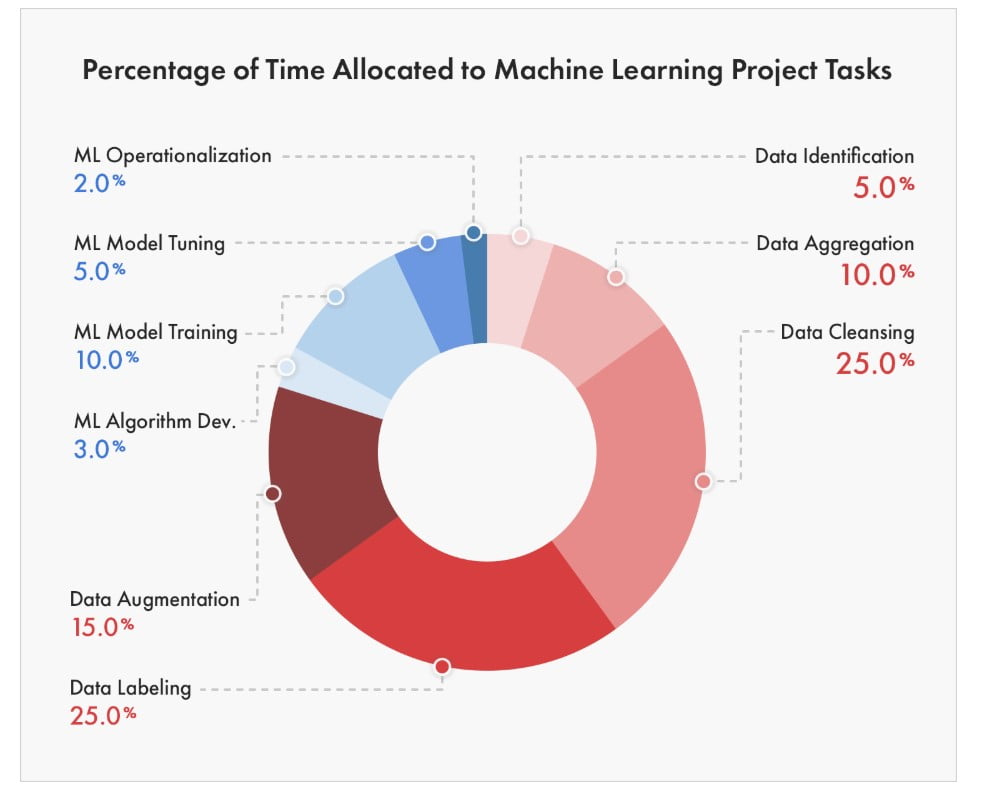
Data Scientists besteden tegenwoordig veel tijd aan het opschonen en voorbereiden van data. Zelfs met dergelijke inspanningen detecteert of corrigeert het opschonen niet alle fouten. Datakwaliteit is cruciaal voor organisaties, anders kun je niet de juiste beslissingen nemen. Met een goede gegevenskwaliteit kunt u erop vertrouwen dat de algoritmen voor meer nauwkeurigheid kunnen zorgen en ook eventuele vooringenomenheid in uw AI-project kunnen verminderen.
Gegevenslabels – Een belangrijk onderdeel van gegevenskwaliteit
Trainingsgegevens kunnen in veel indelingen voorkomen, zoals Spreadsheet, PDF, HTML of JSON, en ze kunnen tekst, afbeeldingen, video en audio bevatten op basis van de behoeften van uw machine learning-toepassing. Deze gegevens moeten worden gelabeld, wat betekent dat u uw trainingsgegevensset moet markeren met belangrijke functies waarmee u uw algoritme kunt trainen. Data labeling wordt ook wel data tagging, annotatie, data processing, etc. genoemd.
De manier waarop gegevenslabels scoren of een gewicht toewijzen aan elk label, is van invloed op de nauwkeurigheid van uw model. Soms moet u datalabelers vinden met de specifieke domeinervaring voor uw behoeften om generieke datalabelers te hebben die met uw klanten kunnen samenwerken om de domeinervaring te krijgen om de score of weging toe te kennen. Zoals u kunt zien, heeft de kwaliteit van gegevenslabels een directe correlatie met de prestaties van uw machine learning-model.
Het pad naar goede gegevens
3 belangrijke elementen kunnen u helpen bij het bouwen van goede gegevens, namelijk People, Process en Tools.
Mensen
Datakwaliteit begint bij de mensen die het werk doen. Afhankelijk van de ervaring die ze hebben en de training die ze krijgen, kan de kwaliteit van gegevens een aanzienlijke impact hebben. Doorgewinterde seniorleden met ervaring in het omgaan met big data voor machine learning-doeleinden kunnen een verschil maken in de vorm van regelmatige training voor anderen in het team.
Proces
Goede QA (Quality Assurance)-praktijken en -processen en kunnen een aanzienlijk verschil maken in gegevenskwaliteit. De veelgebruikte methoden om de nauwkeurigheid en consistentie van gegevens te garanderen, zijn onder meer Gold-sets, consensus en auditing .
Gouden sets of benchmarks meten de nauwkeurigheid door annotaties te vergelijken met een ‘gouden set’ of een doorgelicht voorbeeld.
Consensus, of overlap, meet de consistentie en overeenstemming tussen een groep over de geïdentificeerde gegevens.
Auditing meet zowel nauwkeurigheid als consistentie door een expert de labels te laten beoordelen, hetzij door ze ter plaatse te controleren, hetzij door ze allemaal te beoordelen.
Hulpmiddelen
Het implementeren van de juiste en effectieve tools kan de resultaten verbeteren, de snelheid verhogen en de teamproductiviteit helpen verhogen.
Referenties:
https://www.cloudfactory.com/training-data-guide
https://insidebigdata.com/2019/11/17/how-to-ensure-data-quality-for-ai/
Afbeeldingsbron:
Verwante berichten


















")
