Reading Time : 0 Mins
Artificial Intelligence And Data Quality: The Million Dollar Question

Bibliophile, Movie buff & a Passionate Storyteller.
A question that often comes up in the context of building artificial intelligence systems such as machine learning is “How to get good data to train the algorithms? Data Quality is a challenge. How do we overcome it?”
Both Data Quantity and Data Quality are equally important for Artificial Intelligence systems. While options such as prepackaged data, public crowdsourcing, and private crowds are considered to address the data quantity problem, data quality continues to be a challenge and is likely to become increasingly important.
Why Data Quality is important
Systems like Machine Learning and Deep Learning use very large datasets for both training and testing purposes. Using poor quality data or irrelevant data to train your machine learning system would have a significant impact on the behavior of the system. If your training data is “garbage,” the model outcomes are not going to be different.
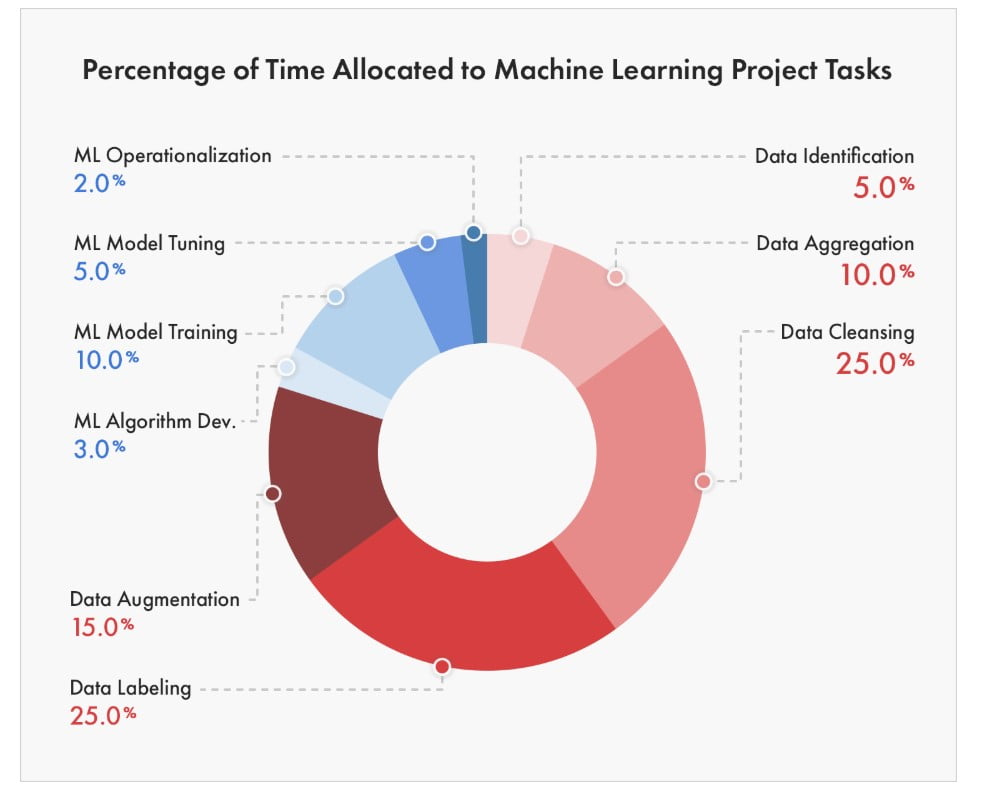
A considerable amount of time is spent by Data Scientists today on cleansing and preparing data. Even with such efforts, cleaning neither detects nor corrects all the errors. Data Quality is crucial for organizations, or you cannot make the right decisions without it. With good data quality, you can be confident that the algorithms can bring in more accuracy and also mitigate any potential bias in your AI project.
Data Labeling – A key component to data quality
Training data can come in many formats such as Spreadsheet, PDF, HTML, or JSON, and they can include text, images, video, and audio based on the needs of your machine learning application. This data needs to be labeled, which means marking your training dataset with key features that will help train your algorithm. Data labeling is also referred to as data tagging, annotation, data processing, etc.
The way data labelers score or assign weightage to each label affects the accuracy of your model. Sometimes you might have to find data labelers with the specific domain experience for your needs to have generic data labelers who can work with your clients in getting the domain experience to assign the score or weightage. As you can see, the quality of data labeling has a direct correlation to the performance of your machine learning model.
The Path to Good Data
3 key elements can help you build good data, namely People, Processes, and Tools.
People
Data Quality starts with the actual people who do the work. Depending on the experience they carry, and the training they receive, the quality of data can have a significant impact. Seasoned senior members with past experience handling big data for machine learning purposes can bring a difference in the form of regular training to others in the team.
Process
Good QA(Quality Assurance) practices and processes and can make a significant difference in data quality. The commonly used methods for ensuring data accuracy and consistency include Gold sets, Consensus, and Auditing.
Gold sets, or benchmarks, measure accuracy by comparing annotations to a “gold set” or vetted example.
Consensus, or overlap, measures consistency and agreement amongst a group on the identified data.
Auditing measures both accuracy and consistency by having an expert review the labels, either by spot-checking or reviewing them all.
Tools
Implementing the right and effective tools can improve outcomes, increase speed, and help increase team productivity.
References:
https://www.cloudfactory.com/training-data-guide
https://insidebigdata.com/2019/11/17/how-to-ensure-data-quality-for-ai/
Image source:
Related Posts


















