Leestijd : 1 minuten
Wat is de rol van machine learning in datawetenschap?

I write about fintech, data, and everything around it
U investeert als nooit tevoren in ML en neemt meer datawetenschappers en machine learning-engineers aan. Er is echter onduidelijkheid over de rol van machine learning en de plaats ervan in de levenscyclus van een data science-project. Hier is een poging om deze onzekerheid op te lossen.
Tegenwoordig benadrukken veel organisaties en industrieën het gebruik van data om hun producten en diensten te verbeteren. Als we het hebben over alleen data science, dan is het alleen data-analyse met behulp van MLOps machine learning. Zowel machine learning als data science moeten hand in hand gaan. Ingenieurs moeten ML en datawetenschap prominent gebruiken om betere en meer geschikte beslissingen te nemen.
In dit artikel maak je kennis met machine learning en datawetenschap, de rol van ML in datawetenschap en hoe ze van elkaar verschillen en toch samenwerken.
In deze blogpost krijg je een overzicht van:
- Wat is machine learning (ML)?
- Waarom is machinaal leren belangrijk?
- Wat is datawetenschap?
- Datawetenschap versus machinaal leren
- De rol van machine learning in datawetenschap
- Belangrijke stappen van machine learning in de levenscyclus van datawetenschap
Oké, laten we beginnen!
Wat is machine learning (ML)?
In eenvoudige bewoordingen kun je machine learning uitleggen als een soort kunstmatige intelligentie (AI) of een subset van AI waarmee softwareapplicaties of apps nauwkeuriger en nauwkeuriger kunnen zijn voor het vinden en voorspellen van resultaten.
Algoritmen voor machine learning gebruiken historische gegevens om nieuwe resultaten of outputwaarden te voorspellen. Er zijn verschillende gebruiksscenario’s voor machine learning, zoals fraudedetectie, detectie van malwarebedreigingen, aanbevelingsengines, spamfiltering, gezondheidszorg en vele andere.
Waarom is machinaal leren belangrijk?
Voor elk bedrijf, elke branche en elke organisatie die gegevens als een primair record of levensader ervan gebruikt, en samen met de evolutie, is er ook een toename van de vraag en het belang ervan. Dit aspect is waarom data-engineers en datawetenschappers machine learning nodig hebben.
Met behulp van deze technologie kunt u in een mum van tijd een grote hoeveelheid data analyseren en risicofactoren berekenen. Machine Learning heeft de manier van data-engineering veranderd op het gebied van dataverwerking, extractie en interpretatie.
Wat is datawetenschap?
Met behulp van moderne technieken en hulpmiddelen behandelt dit studiegebied (datawetenschap) een enorme hoeveelheid gegevens om verschillende en onzichtbare patronen te vinden, informatie af te leiden en zakelijke beslissingen te nemen. Datawetenschap, om modellen te bouwen, maakt gebruik van complexe algoritmen voor machine learning.
Datawetenschap combineert meerdere velden zoals wetenschappelijke methoden, statistieken, data-analyse en kunstmatige intelligentie om de exacte waarde uit data te halen. Datawetenschappers en data-ingenieurs combineren een reeks vaardigheden om gegevens van internet en andere bronnen zoals klanten en smartphones te analyseren en te verzamelen om bruikbare inzichten te verkrijgen.
Datawetenschap versus machinaal leren
| DATA WETENSCHAP | MACHINE LEREN |
|---|---|
| Het is een veld dat gegevens verwerkt en extraheert uit semi-gestructureerde gegevens en gestructureerde gegevens. | Het is een veld dat systemen de mogelijkheid biedt om te leren zonder expliciet geprogrammeerd te zijn. |
| Het heeft een heel analyse-universum nodig. | Het combineert machine- en datawetenschap. |
| De branche houdt zich bezig met data. | Machines gebruiken datawetenschap voor het leren van data. |
| Data science-operaties omvatten het verzamelen, manipuleren, opschonen, enz. | Er zijn drie soorten machine learning: zonder toezicht, onder toezicht en versterking. |
| Het is een brede term die zorg draagt voor gegevensverwerking en zich richt op algoritmen. | ML richt zich alleen op algoritmestatistieken. |
| Voorbeeld : Netflix die datawetenschap gebruikt, is een voorbeeld van deze technologie.
Met de geavanceerde gegevens en analyses die zijn verkregen door het toepassen van datawetenschap, kan Netflix gebruikers gepersonaliseerde aanbevelingen voor films en shows geven. Het kan ook de populariteit van de originele inhoud voorspellen met trailers en miniatuurafbeeldingen. |
Voorbeeld : Facebook dat machine learning gebruikt, is een voorbeeld van deze technologie.
Met behulp van machine learning kan Facebook de geschatte actieratio en de advertentiekwaliteitsscore produceren die voor de totale vergelijking wordt gebruikt. ML-functies zoals gezichtsherkenning, tekstanalyse, gerichte reclame, taalvertaling en nieuwsfeed worden ook in veel praktijkscenario’s gebruikt. |
De rol van machine learning in datawetenschap
Bij datawetenschap draait alles om het blootleggen van bevindingen uit onbewerkte gegevens. Dit kan worden gedaan door gegevens op een zeer gedetailleerd niveau te onderzoeken en de complexe gedragingen en trends te begrijpen. Hier komt machine learning om de hoek kijken.
Maar voordat u gegevens analyseert, moet u de zakelijke vereisten duidelijk begrijpen om machine learning toe te passen.
Maar wat is machine learning?
In eenvoudige bewoordingen helpt machine learning-technologie bij het analyseren en automatiseren van grote hoeveelheden gegevens en het doen van voorspellingen in realtime zonder tussenkomst van mensen.
We gebruiken machine learning-algoritmen in datawetenschap wanneer we nauwkeurige schattingen willen maken over een bepaalde set gegevens, bijvoorbeeld als we moeten voorspellen of een patiënt kanker heeft op basis van de resultaten van hun bloedonderzoek. We kunnen dit doen door het algoritme een grote reeks voorbeelden te geven: patiënten die wel of geen kanker hadden en de laboratoriumresultaten voor elke patiënt. Het algoritme leert van deze voorbeelden totdat het op basis van laboratoriumresultaten nauwkeurig kan voorspellen of een patiënt kanker heeft.
Dat gezegd hebbende, de rol van machine learning in datawetenschap gebeurt in 5 fasen:

Bekijk deze video van onze data science-expert, Sanjeeya Velayutham, om te ontdekken wat machine learning precies is en hoe het past in het grotere geheel van data science.
Laten we eerst eens kijken naar het verzamelen van gegevens.
Het verzamelen van gegevens is de eerste stap van het machine learning-proces. Volgens het bedrijfsprobleem helpt machine learning bij het verzamelen en analyseren van gestructureerde, ongestructureerde en semi-gestructureerde gegevens uit elke database op verschillende systemen. Het kan een CSV-bestand, pdf, document, afbeelding of handgeschreven vorm zijn.
De tweede stap is het voorbereiden en opschonen van gegevens.
Machine learning-technologie helpt bij het analyseren van de gegevens en het voorbereiden van functies met betrekking tot het bedrijfsprobleem bij het voorbereiden van gegevens. ML-systemen begrijpen, wanneer ze duidelijk zijn gedefinieerd, de kenmerken en relaties tussen elkaar.
Merk op dat functies de ruggengraat vormen van machine learning en elk data science-project.
Zodra de gegevensvoorbereiding is voltooid, moeten we de gegevens opschonen, omdat gegevens in de echte wereld behoorlijk vuil zijn en beschadigd zijn met inconsistenties, ruis, onvolledige informatie en ontbrekende waarden.
Met behulp van machine learning kunnen we de ontbrekende gegevens achterhalen en gegevens imputeren, de categorische kolommen coderen, de uitbijters verwijderen, rijen dupliceren en null-waarden veel sneller op een geautomatiseerde manier.
De volgende stap is modeltraining.
Modeltraining hangt af van zowel de kwaliteit van de trainingsgegevens als de keuze van het machine learning-algoritme. Een ML-algoritme wordt geselecteerd op basis van de behoeften van de eindgebruiker.
Bovendien moet u rekening houden met de complexiteit, prestaties, interpreteerbaarheid, computerresourcevereisten en snelheid van het modelalgoritme voor een betere modelnauwkeurigheid.
Zodra het juiste machine learning-algoritme is geselecteerd, wordt de trainingsgegevensset in twee delen verdeeld voor training en testen. Dit wordt gedaan om de bias en variantie van het ML-model te bepalen.
Als resultaat van modeltraining kom je tot een werkend model dat verder gevalideerd, getest en ingezet kan worden.
Nadat de modeltraining is voltooid, zijn er verschillende metrische gegevens om uw model te evalueren. Onthoud dat het kiezen van een metriek volledig afhangt van het modeltype en het implementatieplan. Hoewel het model is getraind en beoordeeld, betekent dit niet dat het klaar is om uw bedrijfsproblemen op te lossen. Elk model kan verder worden verfijnd voor een betere nauwkeurigheid door de parameters verder af te stemmen.
De laatste en meest cruciale fase van een data science-project is modelvoorspelling.
Wanneer we het hebben over modelvoorspelling, is het essentieel om voorspellingsfouten (bias en variantie) te begrijpen.
Door een goed begrip van deze fouten te krijgen, kunt u nauwkeurige modellen bouwen en de fout vermijden om het model te veel of te weinig aan te passen.
U kunt de voorspellingsfouten verder minimaliseren door een goede balans te vinden tussen bias en variantie voor een succesvol data science-project.
- Machine learning analyseert en onderzoekt automatisch grote hoeveelheden gegevens.
- Het automatiseert het data-analyseproces en maakt voorspellingen in realtime zonder enige menselijke tussenkomst.
- U kunt het datamodel verder bouwen en trainen om realtime voorspellingen te doen. Op dit punt gebruikt u algoritmen voor machine learning in de levenscyclus van gegevenswetenschap.
In de volgende sectie zullen we de belangrijkste stappen bestuderen die betrokken zijn bij een typische machine learning-workflow.
Belangrijke stappen van machine learning in de levenscyclus van datawetenschap
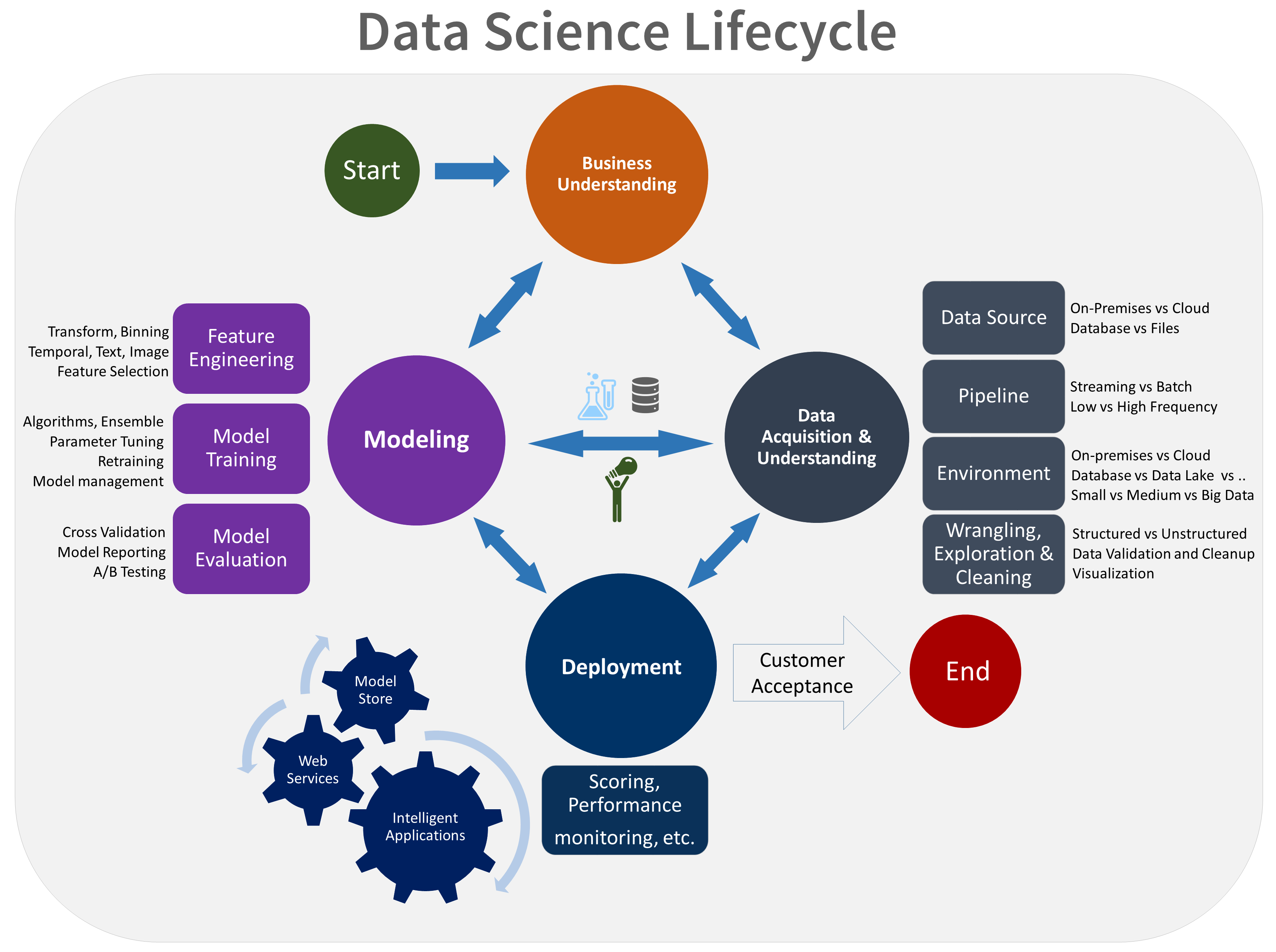
Belangrijke stappen van machine learning in de levenscyclus van datawetenschap
Bron: Microsoft
Het bovenstaande diagram is de grafische weergave van hoe u het gegevensmodel kunt trainen en gegevens kunt verkrijgen bij het nemen van zakelijke beslissingen. Laten we leren hoe we het kunnen uitvoeren:
Gegevens verkrijgen → Gegevens voorbereiden → Trainingsmodel → Gegevens testen → Verbeteren
- Gegevensverzameling: Het staat bekend als de basis of primaire stap. Het is essentieel om relevante en betrouwbare gegevens te verzamelen die van invloed zijn op de resultaten.
- Data voorbereiding: De algemene eerste stap van gegevensvoorbereiding is het opschonen van gegevens. Het is een essentiële stap voor het voorbereiden van de gegevens. Deze stap zorgt ervoor dat gegevens foutief zijn en vrij van corrupte gegevens.
- Modeltraining: In deze stap begint het leren van gegevens. U kunt training gebruiken om de waarde van de uitvoergegevens te voorspellen. U moet deze training van de modelstap herhalen en dit keer op keer doen om te verbeteren en nauwkeurigere voorspellingen te krijgen.
- Gegevens testen: Zodra u de bovenstaande stappen hebt voltooid, kunt u de evaluatie uitvoeren. De evaluatie zorgt ervoor dat de dataset die we krijgen zal presteren in real-life toepassingen.
- Voorspellingen: Als u het model eenmaal hebt getraind en geëvalueerd, betekent dit niet dat de dataset perfect is en klaar om te worden ingezet. Je moet het verder verbeteren door te tunen. Deze fase is de laatste stap van machine learning. Hier beantwoordt de machine al uw vragen door te leren.
Gevolgtrekking
Organisaties omarmen tegenwoordig het potentieel van data om hun producten en diensten te verbeteren. Het belangrijkste motto van dit artikel was om uit te leggen hoe Data Science en Machine Learning elkaar aanvullen, waarbij machine learning het leven van een Data Scientist gemakkelijker maakt.
In sommige real-life scenario’s – online aanbevelingsengines, spraakherkenning (in Siri en Google Assistant), detectie van fraude in alle online transacties – werken datawetenschap en machine learning samen en geven ze waardevolle gegevensinzichten. Het is dus niet verkeerd om te concluderen dat Machine Learning gegevens kan analyseren en waardevolle inzichten kan verkrijgen.
Zo zal machine learning in de nabije toekomst een van de meest gewilde technologieën worden. Het zal in de toekomst de meest productieve toepassingen maken en de overhand krijgen als een van de meest gevraagde technologieën in datawetenschap.
We hopen dat je dit artikel leuk vindt en leert hoe machine learning een intrinsiek onderdeel is van data science! Boek een ontdekkingsservice met onze data-architecten vandaag en een voorsprong op de concurrentie. Maak het eenvoudig en maak het snel.
Verwante berichten


















")
