
Leestijd : 1 minuten
OCR – optische tekenherkenning
Een groot probleem waarmee veel bedrijven tegenwoordig worden geconfronteerd, is het onvermogen om gegevens op te halen die vastzitten in gescande documenten en afbeeldingen. Er zijn twee manieren om gegevens te extraheren:
- Handmatige gegevensextractie
- Geautomatiseerde gegevensextractie
Aangezien het handmatige proces veel nadelen heeft, hebben we automatiseringssoftware voor gegevensinvoer nodig die helpt om gegevens uit gescande documenten te extraheren en te automatiseren op basis van bedrijfsprocessen.
De uitdaging is niet alleen om gegevens uit gescande documenten te extraheren, maar ook om deze nauwkeurig te extraheren. Geautomatiseerde gegevensinvoersystemen zijn in staat om informatie uit verschillende gegevensbronnen (PDF-bestanden, gedrukte documenten, e-mails, websites, …) te lezen en de gegevens op te nemen in een meer aangepaste gegevensopslag (databases, spreadsheetbestanden, …).
Een dergelijke software/technologie is OCR . Optical Character Recognition, of OCR, is een technologie waarmee u verschillende soorten documenten, zoals gescande papieren documenten, PDF-bestanden of afbeeldingen die met een digitale camera zijn vastgelegd, kunt converteren naar bewerkbare en doorzoekbare gegevens. Voor degenen die zijn begonnen met het verkennen van OCR Android-applicaties, zal dit artikel je helpen OCR te vinden als een Android-applicatie voor het converteren van zowel handgeschreven als gedrukte gegevens in afbeeldingen naar tekst .
Wat is OCR en hoe werkt het?
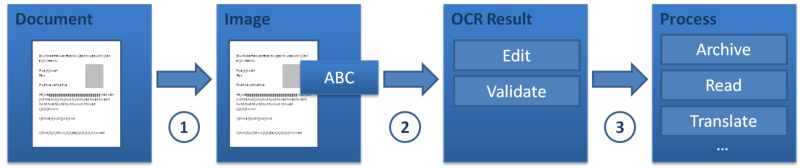
OCR-optische tekenlezer/herkenning
Optical Character Reader (OCR) is een softwareprogramma dat Optical Character Recognition gebruikt om specifieke tekens op vellen te lezen en deze om te zetten in digitale tekens. OCR-software kan worden gebruikt om afgedrukte gegevens om te zetten in digitale gegevens zonder te typen, zoals van een gescand document. Het is erg handig wanneer het nodig is om tekst uit boeken, gescande documenten enz. te digitaliseren. Zodra OCR de tekst extraheert, kan deze in verschillende formaten worden gekopieerd of opgeslagen.
Werkstroom :
Afbeelding vastleggen, randen detecteren, tekst uit een afbeelding ophalen, vertalen met Google API en resultaten weergeven.
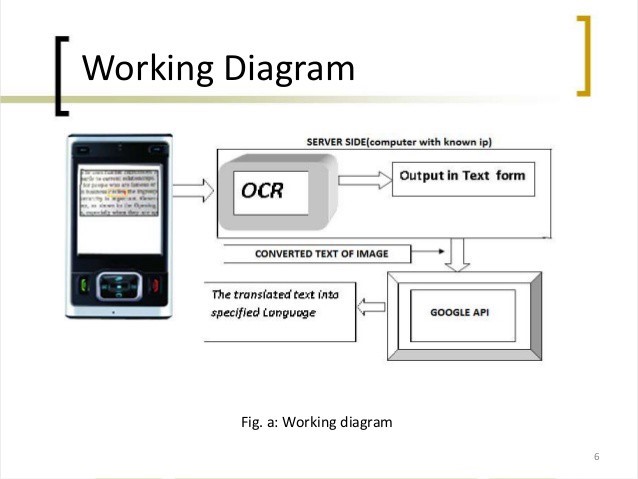
We hebben een Android-applicatie nodig die de volgende beperkingen moet ondersteunen:
- Handgeschreven inhoudstekst digitaliseren
- API-ondersteuning hebben
- Tool Kit-ondersteuning hebben
- Ondersteuning voor machine learning of Deep Learning
Ik heb samen met mijn team enkele voorbeeldafbeeldingen van Google genomen om te controleren. Met die voorbeeldafbeeldingen hebben we geëxperimenteerd met verschillende Android-applicaties, zoals:
- CamScanner
- TekstFee
- Google Keep
- OCR-tekstscanner
- Tekstscanner
- Kantoorlens
- Online OCR
- Adobe-scanner
- Evernote-scan
- OCR-ruimte
- Google-API

Fig.b.tekstafbeelding vastleggen voor conversie
Naast de voorbeeldafbeelding hebben we een tekstdetectiecode nodig om het proces te testen. Tekstdetectie voert optische tekenherkenning uit. Het detecteert en extraheert tekst in een afbeelding met ondersteuning voor een breed scala aan talen. Het beschikt ook over automatische taalidentificatie. De tekstdetectiecode (JAVA) die we voor ons project hebben gebruikt, wordt hieronder gedeeld:
public static void detectText (String filePath, PrintStream out) genereert Exception, IOException {
Lijstverzoeken = nieuwe ArrayList<>();ByteString imgBytes = ByteString.readFrom (nieuwe FileInputStream (filePath));
Afbeelding img = Afbeelding.newBuilder().setContent(imgBytes).build();
Feature feat = Feature.newBuilder().setType(Type.TEXT_DETECTION).build();
AnnotateImageRequest-verzoek =
AnnotateImageRequest.newBuilder().addFeatures(feat).setImage(img).build();
verzoeken.add(verzoek);probeer (ImageAnnotatorClient-client = ImageAnnotatorClient.create()) {
BatchAnnotateImagesResponse response = client.batchAnnotateImages(verzoeken);
Lijstreacties = response.getResponsesList();voor (AnnotateImageResponse res: reacties) {
if (res.hasError()) {
out.printf(“Fout: %sn”, res.getError().getMessage());
opbrengst;
}// Voor een volledige lijst met beschikbare annotaties, zie https://g.co/cloud/vision/docs
for (EntityAnnotation annotatie: res.getTextAnnotationsList()) {
out.printf(“Tekst: %sn”, annotation.getDescription());
out.printf(“Positie: %sn”, annotation.getBoundingPoly());
}
}
}
}
Volgens onze verkenning hebben alle hierboven besproken toepassingen de mogelijkheid om het afgedrukte recept in PDF te digitaliseren, maar het is niet gelukt om het handgeschreven recept te digitaliseren. Om dat probleem op te lossen, hebben we onderzoek gedaan en ontdekt dat ICR & IWR helpt om dat probleem op te lossen.
Wat zijn ICR en IWR?

ICR
Intelligente tekenherkenning ( ICR ) is een geavanceerde optische tekenherkenning of liever meer specifiek handschriftherkenningssysteem waarmee lettertypen en verschillende handschriftstijlen tijdens de verwerking door een computer kunnen worden geleerd om de nauwkeurigheid en herkenningsniveaus te verbeteren (machine / diep leren).

IK WR
Intelligente woordherkenning (IWR) kan niet alleen gedrukte handgeschreven informatie herkennen en extraheren, maar ook cursief handschrift. ICR herkent het karakterniveau, terwijl IWR werkt met volledige woorden of woordgroepen. In staat om ongestructureerde informatie van alledaagse pagina’s vast te leggen, zou IWR meer geëvolueerd zijn dan handafdruk ICR.
Overzicht :
Dit artikel bevatte veel over de voor- en nadelen van verschillende OCR Android-apps voor het converteren van een afbeelding naar tekst en ook over ICR, IWR. Ik zal in mijn aanstaande blog vertellen over de geëxperimenteerde resultaten van de respectievelijke apps.
Bedankt voor het lezen en blijf op de hoogte voor meer. :)

I write about fintech, data, and everything around it | Assistant Marketing Manager @ Zuci Systems.
Deel deze blog, kies uw platform!
gerelateerde berichten















")

")

