Leestijd : 0 minuten
Lessen uit ons AI-webinar over QA

An INFJ personality wielding brevity in speech and writing.
Ik val absoluut in het kamp van het denken van AI als het vergroten van de menselijke capaciteiten en capaciteiten. – Satya Nadella
Onze nieuwste QA-webinar over ‘Hoe AI defectdetectie verandert?’ had bijna een soortgelijk thema. Voor het geval je het live hebt gemist, hier zijn de lessen van ons AI-webinar over QA.
De 1 uur durende livesessie had 90+ deelnemers geregistreerd, en 25% van hen keek live mee. De presentator, Vasudevan Swaminathan , leidde de aanwezigen door de noodzaak van defectdetectie en hoe kunstmatige intelligentie dat verandert.
Het begon allemaal op 9 september 1947, de dag waarop ’s werelds eerste bug werd gevonden en de evolutie van de defecten, die door de jaren heen een fortuin kostte voor bedrijven, wat de noodzaak van defectdetectie opriep.
Zoals het aforisme luidt: ‘Softwaretesting bewijst het bestaan van bugs, niet hun afwezigheid’. Het bestaan van defecten en de ernstige gevolgen ervan hebben de methoden voor het testen van software veranderd. Van Waterfall-methodologie tot het huidige DevOps-tijdperk, we hebben het allemaal gezien. De nieuwste en wat wordt beschouwd als de toekomst van softwaretesten is AI. De overgang naar de adoptie van AI bij testen is tegenwoordig geen modewoord meer.
AI vertrouwt op gegevens.
Hoe meer en diverser de gegevens in de vorm van defecten uit het verleden, trends in defecten, enz. die naar het Machine Learning-model worden gevoerd, des te beter is het resultaat.
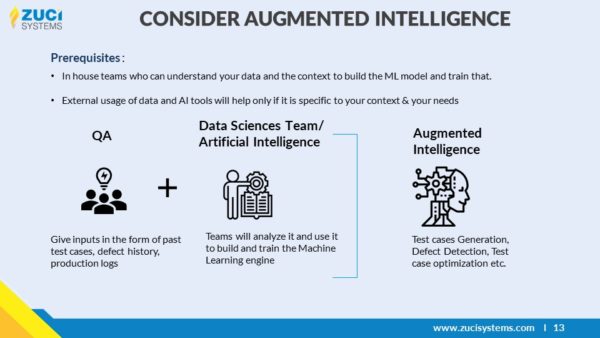
Door samen te werken met mensen kan AI de datageletterdheid van het hele personeelsbestand verhogen. Hoewel sommige AI-toepassingen alleen afhankelijk zijn van machineautomatisering, vereisen de meeste complexe zakelijke problemen zoals defectdetectie menselijke interactie en perspectief. En daarom noemen we het liever Augmented Intelligence in plaats van Artificiële Intelligentie.
Tegen het einde van het webinar waren er enkele interessante vragen van de aanwezigen.
Q1: Voor begeleid leren moet u gelabelde gegevens hebben. Ik denk dat je suggereert dat de QA-resultaten van eerdere sprints de bron zullen zijn van de labels op de gegevens. Kan dat helpen bij het identificeren van defecten in toekomstige sprints, waar nieuwe defecten kunnen worden geïntroduceerd?
A1: Labelen is zeker iets wat we doen. Maar dat doen we voor de testgevallen (voorlopig) en niet voor de resultaten (omdat we een conservatieve aanname hebben gedaan bij het toewijzen van een testgeval aan een testresultaat). Aangezien de testgevallen al zijn toegewezen aan bestaande problemen (regressie indien aanwezig?), churn-rate van de codebase, krijgen we soms toegang tot het voorspellen van de toekomst (we kiezen voorlopig alleen de uitbijters). Ja, het helpt, maar we werken eraan om de beschikbare modellen te gebruiken om de toekomst te voorspellen en op dit moment hebben we gemengde resultaten.
Vraag 2: Kun je een realtime voorbeeld geven hoe AI helpt bij het automatiseren van een basisinloggebruik?
A2: Login testautomatisering – Het belangrijkste voordeel van AI of op leren gebaseerde oplossingen waar Zuci zich op richt, is het genereren van testcases, niet om ze te automatiseren. Dit zijn de use cases waar Zuci zich op richt,
-
- Een betere manier vinden om het ene document (een testcase) boven een ander document te promoten
- Of het ene document samen met het andere groeperen,
- Of een document maken (een testcase genereren)
V3: Welk bedrijf heeft de Spider AI-tool gebouwd?
A3: Spider AI-tool – ‘Spider AI-tools’ zijn veelgebruikte crawler-tools die u aantreft in Search Engine Optimization en andere gebieden. In het kader van het identificeren van testgevallen gebruikt Zuci een vergelijkbare oplossing om de optimale te herkennen.
Verwante berichten



















